
In the future world many things changed, but algoritms are still popular
The theme of the post is competitive programming, the theme of the gif images is cyberpunk. Get over here.
I’ve been doing competitive programming for some years, and have never regretted it. Competivive programming is pretty cool. If you don’t believe in it, I can prove it. Just let’s go!
Competitive programming is interesting
If someone does CP seriously, they learn a lot of interesting things. Data structures, graph theory, string algorithms, as well as dynamic programming, game theory, combinatorics… The list is pretty big.
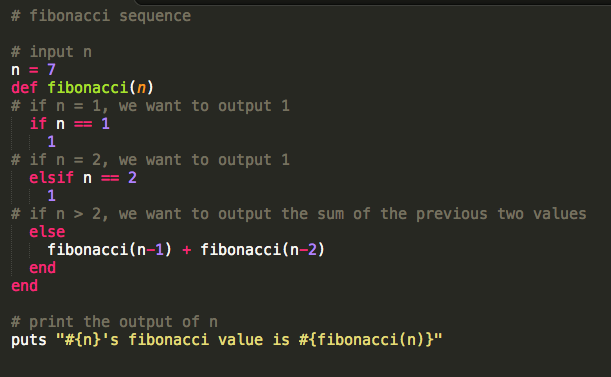
And he knows why this code is as slow as an old phone with Android 2.3.2
Competitive programming helps understand the code better and keeps the brains turned on

Something went wrong, and I can’t handle it for two hours
Rubber Duck on steroids
Competitions have tight time limits. If you didn’t debug your code in time, you lost valuable time/points, or got bigger penalty. The brains turned on CP will not stretch out time up to hour to find a bug.
You need to understand how it all works
A huge number of programmers have no idea how really these std::map/TreeMap and std::set/TreeSet work, not even speaking about other things. Some people treat it like black magic. Because of this, they allow themselves to write code which runs much slower than it could.

Hey, what is an array shift?
Well, I’m not going to go far to find an example. Imagine what we have an object of std::vector/ArrayList of 100’000 elements. We have to write a piece of code that sometimes deletes the first or the last element (suppose we don’t want to clear the list instantly, only one by one). If you’re not into data structures, you’d think that removing the first and the last element is the same. Let’s remove the first element every time. And there is a surprise - it turns out that this code works a few seconds! If we delete the last element, it works almost instantly. A slightly experienced programmer understands immediately why it happens. (Though, if we use double-linked list, it works fast in both cases).
To be continued
There are other side effects, like the ability to write code fast, but it isn’t the subject of this post anyway.
Competitive programming is prestigious

CP has never been something underground. There are a lot of well-known contests with interesting tasks are held every year. The most famous of them is ACM ICPC for university students and IOI for high school students. In big contests like Google Code Jam, Facebook Hacker Cup, top contestants get paid trip to the “onsite” - the final round. Some strong companies hold domestic contests, in Russia there are VK Cup, Yandex.Algorithms and Russian Code Cup, they’re all made by the country’s finest IT companies. Of course, everyone can take part in regular online contests on sites like TopCoder or Codeforces.
Contests systems are different, but they have the same point - it’s necessary to solve tasks fast and without mistakes.
What does a typical task look like?
![]()
Legends and sagas
What is a task (Sometimes called a problem)? We get a bunch of numbers and strings from the input stream or a file, and we have to write a program that reads the data, somehow works with it and writes other data (the answer) to an output stream/a file. The description of the task is named “legend”. Usually a few examples (1-3) are suggested after the legend. The legend creates a mathematical model of the task, that is, it says, “imagine that the next $N$ numbers are the elements of the array $A$, and the next $M$ numbers are the array $B$”.

Recommended to solve
When Google Code Jam engineers were giving a talk about the competitions, they considered a pretty good problem from one of their round - Evaluation.
An unordered list of assignment statements is given. The task is to determine if it’s possible to put the statements in an order in which all variables can be evaluated correctly, without using another undefined variable.
For example, if these statements are given:
1
2
3
a=f(b,c)
b=g()
c=h()
The answer is “possible”. This is a valid order:
1
2
3
b=g()
c=h()
a=f(b,c)
Here all the variables calculated correctly, and to calculate $a$ we use already defined $b$ and $c$. Therefore, the order below is invalid, because we’re going to evaluate variable $a$ when $c$ is undefined:
1
2
3
b=g()
a=f(b,c)
c=h()

Scoring
There are up to 20 tests in every file. If we’re able to find the answer for one hundred statements ($n \leq 100$), we get $12$ points. If there are up to one thousand statements ($n \leq 1000$), we get $12+15=27$ points. So, if we come up with a solution which isn’t optimal enough, we may get partial score. It’s assumed that $12$ points is given for a $O(n^3)$ solution, and $27$ points is given for a $O(n^2)$ solution. Let’s write better solution at once.
Hack!
1
2
3
4
5
6
7
8
9
10
11
12
#include <bits/stdc++.h>
using namespace std;
int main() {
int t;
cin >> t;
for (int i = 0; i < t; i++) {
cout << "Case #" << i + 1 << ": ";
cerr << "Test #" << i + 1 << endl;
cout << (solve() ? "GOOD" : "BAD") << endl;
}
}
solve() reads the test and calculates the answer.
It’s better to write a helper function for to split strings, so val=func(argx,argy) transforms to {"val", "func", "argx", "argy"}:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
vector<string> crop(const string& s) {
vector<string> vec;
string cur = "";
for (size_t i = 0; i < s.size(); i++) {
if (s[i] < 'a' || s[i] > 'z') {
// If s[i] is not a lowercase English letter
if (!cur.empty()) {
vec.push_back(cur);
cur = "";
}
} else {
cur += s[i];
}
}
return vec;
}
Graph theory
How can we solve it? It’s time for the popular and legendary graph theory.

Let’s represent our input data as a graph! Every variable is a vertex now, and we create a directed edge from each vertex to every dependent variable (other vertices).
Building the model
Our example looks this way - there are three vertices a, b and c, and two edges, from a to the other vertices. We can represent any test in the same way. Intuitively, the task can be solved by this method - we look at the graph and determine if there is a vertex without edges to other undefined vertices. If such a vertex was found, then we mark its variable as “defined” and go further.

Finding the answer
If we have undefined variables, but can’t find any vertex without edges to undefined variables, it means that we have a cycle, that is unsolvable dependencies. Somewhere x depends on y, y depends on z, and z depends on x, like this. Of course, if we defined all the variables, then the solution exists.
Finishing the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
bool solve() {
int n;
cin >> n;
vector<string> source(n); // input lines
map<string, int> indices; // map "variable name" -> "index"
vector<vector<string>> deps_raw(n); // list of dependencies (as strings)
vector<set<int>> deps(n); // list of dependencies (as indices)
for (int i = 0; i < n; i++) {
string s;
cin >> s;
source[i] = s;
vector<string> variables = crop(s);
string name = variables[0];
indices[name] = i;
vector<string> var_names;
for (size_t z = 2; z < variables.size(); z++)
var_names.push_back(variables[z]);
deps_raw[i] = var_names;
}
for (int i = 0; i < n; i++) {
for (auto dep : deps_raw[i]) {
if (!indices.count(dep))
return false;
}
}
for (int i = 0; i < n; i++) {
set<int> deps_set;
for (auto dep : deps_raw[i])
deps_set.insert(indices[dep]);
deps[i] = deps_set;
}
// main loop here!
vector<bool> used(n);
for (int count = 0; count < n; count++) {
int v = -1;
for (int i = 0; i < n; i++) {
if (used[i])
continue;
if (deps[i].empty()) {
v = i;
break;
}
}
if (v == -1)
return false;
cerr << count << "-th line: " << source[v] << endl;
used[v] = true;
for (int i = 0; i < n; i++) {
if (!used[i]) {
if (deps[i].count(v))
deps[i].erase(v);
}
}
}
return true;
}

Compile in your IDE or using the console g++ -std=c++11 main.cpp -o main, launch the program with ./main <input_file >output_file.
Output in the console from the author’s example:
1
2
3
4
5
6
7
8
9
Test #1
0-th line: b=g()
1-th line: c=h()
2-th line: a=f(b,c)
Test #2
Test #3
Test #4
0-th line: x=f()
1-th line: y=g(x,x)

That’s all, thanks for reading! Stay tuned…
:wq